Our first community update - Signal
Excited to launch our first newsletter. We are delighted to have crossed 1.6k stars on GitHub, growing more than 30% last month. Catch up on what we're upto at SigNoz!

We are pleased to release the first issue of our newsletter. With this newsletter, we aim to let our community know what we've been upto. A roundup of major releases, issues, comments as well as some interesting stuff from our blog section. So without further ado, let's get down to it!
What we shipped
In the last few weeks, 2 of our major releases include service maps and external API monitoring.
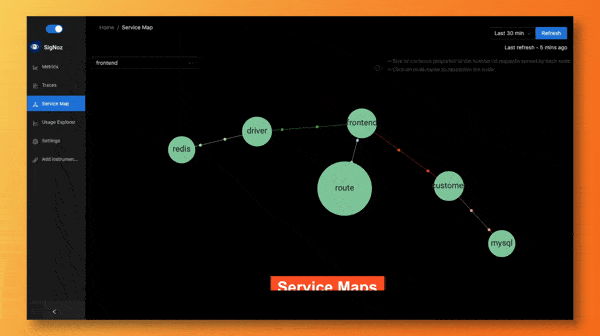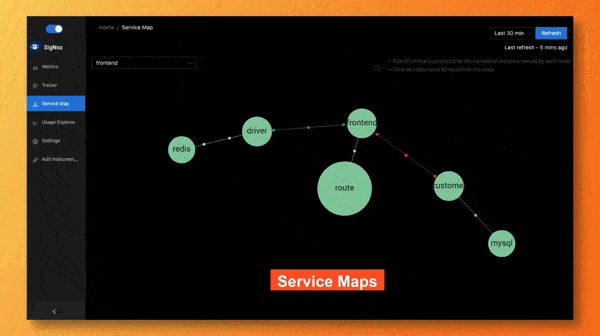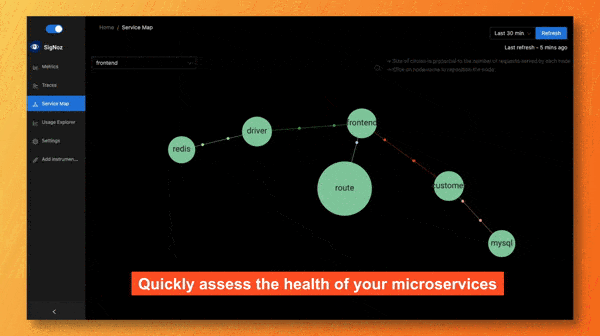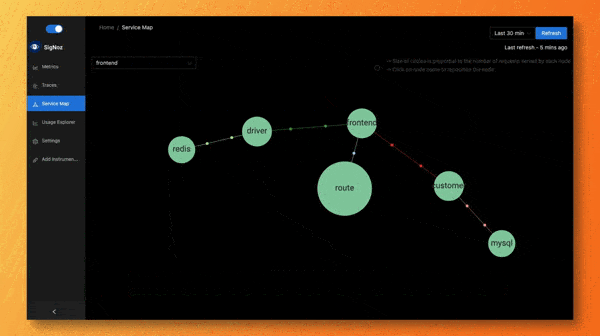
Service Maps
Service maps is one of the coolest feature of the SigNoz dashboard. With just a glance, you can figure out the services that needs your attention.
External API Monitoring
External API monitoring provides you a separate dashboard for seeing metrics for any external API you may be calling e.g. Paypal, Twillio, etc.
This helps you quickly isolate if the issue is due to internal services or on any external dependencies.
Featured Issue
Alerts as Code which can be version controlled for teams to look back!
One of our favorite issue to work on is building an alert manager. Alerting is an important feature of any APM tool and at SigNoz we want to build an alert manager that helps you create actionable alerts with high signal-to-noise ratio.
As we design the details of this, would love to hear from you what features would you want to see in the alert manager and what you find missing in current tools. Do add your comments in this issue.
What's upcoming?
ClickHouse support
We had lots of interest from the community in adding support for ClickHouse which would make SigNoz less resource intensive compared to current architecture based on Kafka & Druid.
We heard you and have already started exploring design details for ClickHouse support. Watch out for more updates in the coming newsletters 🤓
SigNoz News
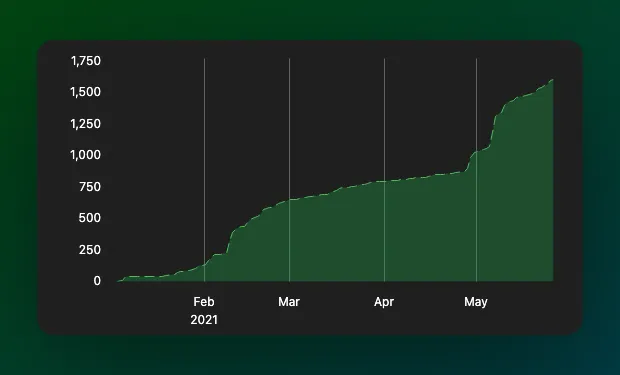
We are delighted to have crossed 1.6k stars on GitHub, growing more than 30% last month 🎉. We can't thank you all enough for this! 👏
From our blog
As this is our first edition, we want to share with you why we decided to build a full stack open source observability platform and how we are going about building it.
We first went about building an observability tool using existing open source solution. We set up metrics using Prometheus + Cortex and we set up distributed tracing using Jaeger.
But the achieved solution was limited in its use cases as well as difficult to set up. Prometheus alone can not be used for root cause analysis and UI of Jaeger is minimal.
Read more about these limitations and how we are solving those at SigNoz here:
Genesis of SigNoz - A full stack open source observability platform
Contributors
Shout out to Anwesh and Nidhi , new contributors to the project for making the project a wee bit better than where they found it. Thanks for your time and commits!
Thank you for taking out the time to go through our first newsletter :) If you have any feedback or want any changes with the format, create an issue here.
Also, come join us in our slack community, we would love to host you there :)

