Observability - Insurance vs Growth driver?
When you think about observability? Do you just think of it as an insurance? Or do you think it can also drive growth for the business?
Working with many customers and users trying to get better at Observability, there are two mindsets I see:

-
People who see Observability as an insurance
e.g. Trying to find the root cause when something goes wrong
-
People who see observability as a growth driver
e.g Trying to solve a business issue which improves usage, monetization.
Let’s explore
Observability as a Insurance
A typical scenario here is, you find that your APIs are suddenly getting slower. Your API latency alerts are firing. If you didn’t have observability systems in place, you would be blind. You would be in a fix to find out where the problem is, as you would have multiple micro-services in place and it would be difficult to segregate out cause from effect.
But since you have observability tools in place, you are in a much better place. You can find out which machines has potentially exceeded CPU limit or there is DB call which is getting blocked and hence taking a lot of time. Or it could even be a third party API which is responding slowly and hence is making your own APIs get a lot slower.
Don’t get me wrong. These are important use cases. And when your hair is on fire (as is mostly the case for production issues), having all this information on your fingertips is a life saver.
But this is still a very limited view of what observability can do for your business.
Observability as a Growth Driver
Here’s a typical senario
Suppose you are a ride sharing app. You have a complicated logic for deciding how rides are allocated to drivers. The logic involves calls to multiple services.
Your business lead comes to you and wants to understand - why a set of drivers have not been allocated any rides in the recent past? You don’t have a good answer, as the assignment is decided by a complex set of logic.
If your services are powered by distributed tracing, you can understand how actual API calls are taking place and figure out what paths a request for a driver allocation is taking and why? This will help you answer the question from your business counterpart.
You can also use observability to try to identify tech debt.
For example, you can monitor p95 latencies of set of APIs and prioritise improving those APIs which have the worst latency and is called the most number of time. This is a good framework to prioritise how you can improve customer experience.
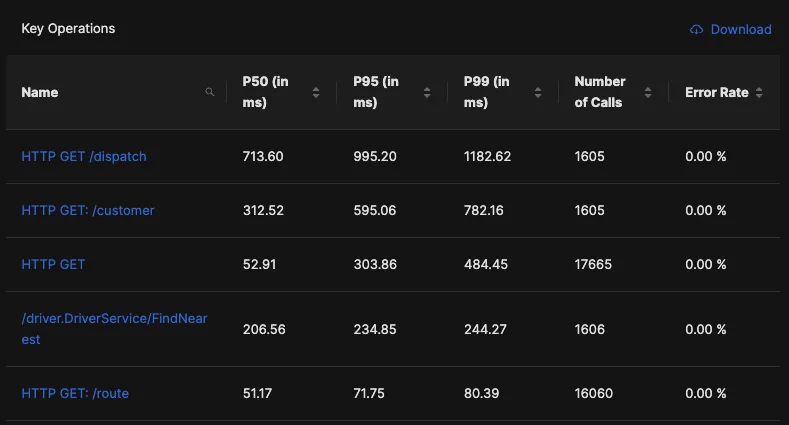
Having an observability tool also helps you understand which part of your request calls is taking most time and hence a very good indicator of where to focus your energies first.
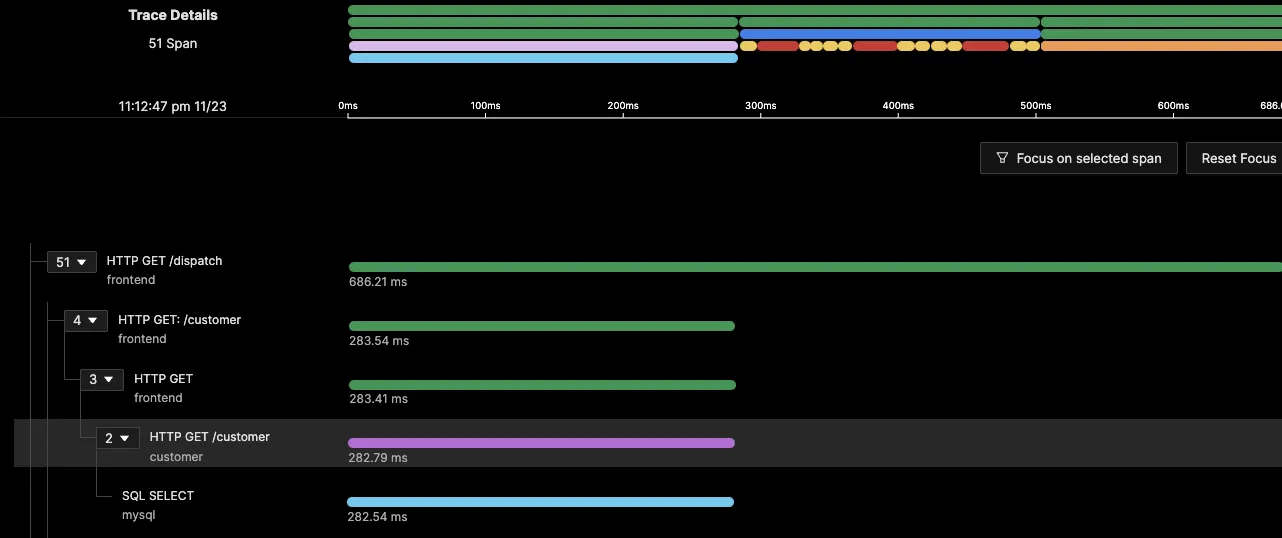
In this trace graph, the SQL statement seems to be the cause of the most time taken
The second set is much smaller today, but lot more powerful. Users and customers in this category come up with so many interesting use cases.
So, next time your business leader asks you - why are we paying so much for this tool? What is the business value for it? ( I know, those are always the tough ones)
Don’t hide behind your desks. May be make a list of use cases like above and send an email. Their eyes may well light up 🙂
I think this is where the future of Observability tools lie: driving business growth.
Further Reading
Complete Guide on OpenTelemetry Collector
